Data pipelines
Vi bruker begrepet "pipeline" om en prosess der data flyter fra ett sted via et eller flere steg til et annet sted. Dette kan bety ren innhenting av rådata, transformering til et dataprodukt, eller begge deler.
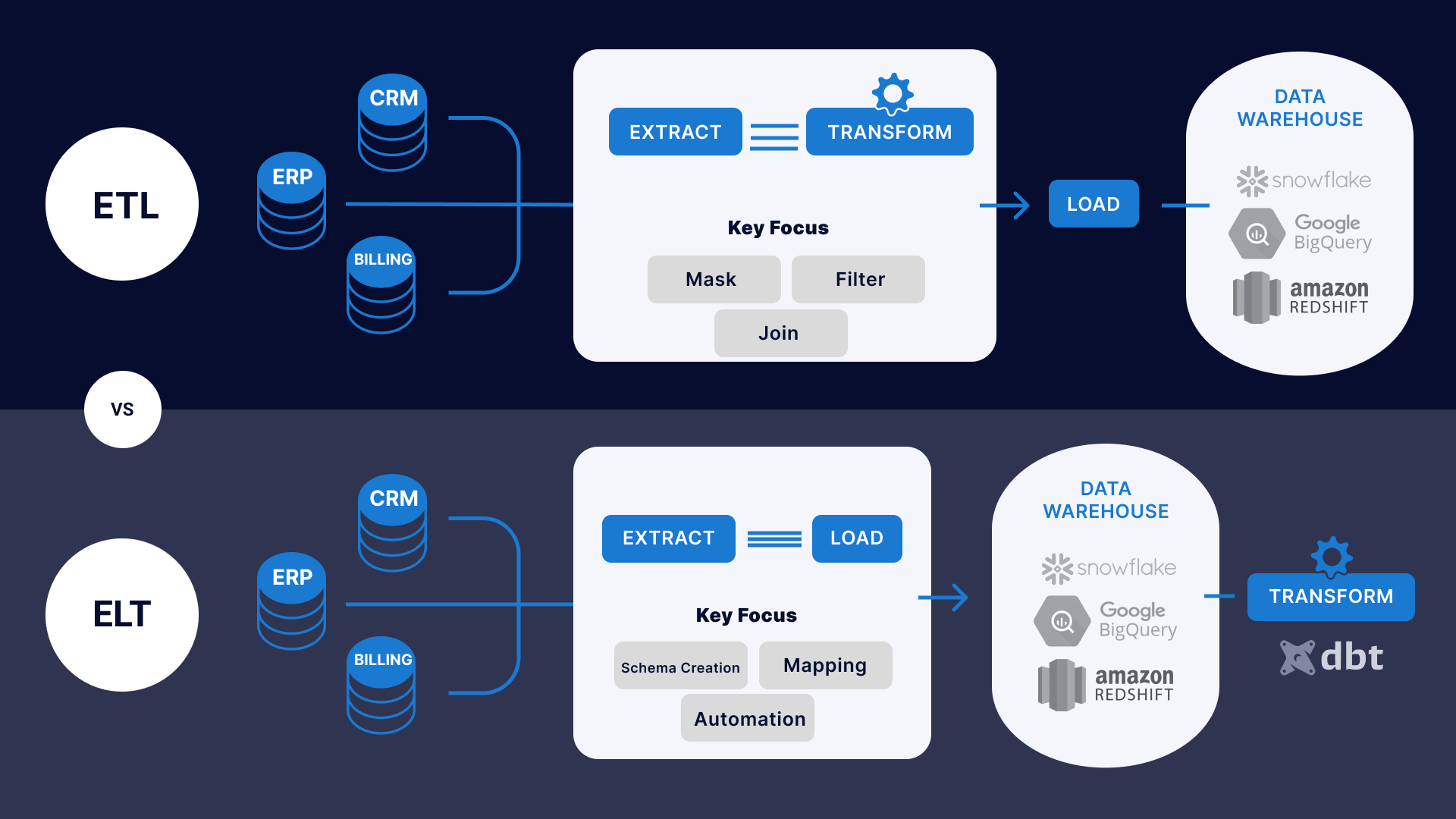
Extract, Load, Transform
På Saga bruker vi en metode kalt "Extract, Load, Transform" (ELT) for å innhente og prosessere data.
 kilde: https://www.striim.com/blog/etl-vs-elt-differences
kilde: https://www.striim.com/blog/etl-vs-elt-differences
I tradisjonelle datavarehus brukte man ofte "Extract, Transform, Load" (ETL), som innebærer at data ble transformert før det havnet i datavarehuset. Det sparer plass, men gjør det også vanskeligere å jobbe med rådata.
De fleste moderne skydataløsninger bruker i stedet ELT, der rådata lastes inn i skyen og transformeres/prosesseres videre derfra.
Vi skal nå se på hva dette betyr for Saga og hvordan de ulike stegene kan implementeres.
Extract & Load = Ingest
Data må hentes ut fra interne systemer og lastes inn i Saga. Dette kan skje ved at en pipeline på Saga tar kontakt og ber om data (pull-basert), eller at Saga har satt opp et mottak som systemet kan sende data til (push-basert).
Denne prosessen, som innebærer både "extract" og "load"-stegene, kalles "data ingestion", eller bare "ingest", og ender med at rådata er tilgjengelig på Saga, typisk i Google Cloud Storage eller i BigQuery. Merk at innholdet i dataene ikke skal endres i særlig grad under ingest. Det betyr blant annet at man skal beholde de samme feltene som man opprinnelig hadde i datakilden.
Transform
Når rådata er tilgjengelig på Saga, kan den transformeres og kombineres med andre data for å lage nye dataprodukter. Denne prosessen kalles "transform".
Pipelines i Saga
Dersom du har tenkt å lage pipelines i Saga kan du begynne med å lese dokumentasjonen om hvordan bygge pipelines i Saga.