Hvordan lage pipelines i Airflow
Pipelines i Airflow
Du kan se ditt teams kjørende pipelines her:
🚧 Pipelines i STM 🏁 Pipelines i PROD
Hvordan er pipelines bygd opp i Airflow?
Pipelines i Airflow bygges opp som en "Directed Acyclic Graph" (DAG). DAG er en graf med bokser og piler, som i eksempelet under. Boksene representerer steg i en pipeline, og pilene viser avhengighetene mellom stegene.
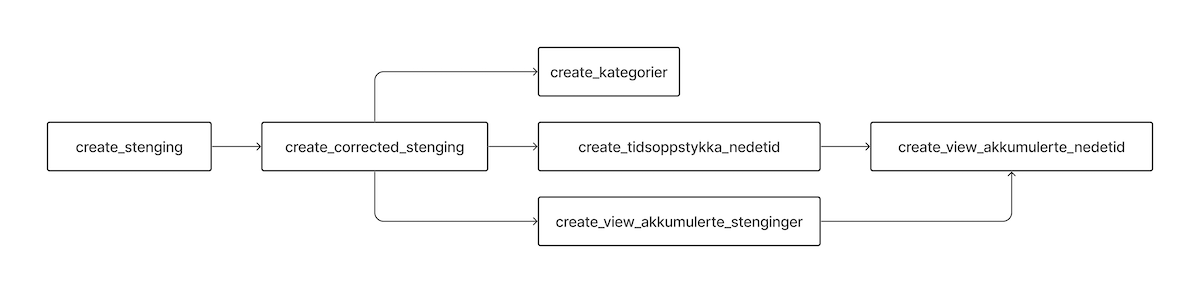
Hvordan kan en DAG se ut?
En DAG er et Python-script som slutter på .dag.py. De forskjellige stegene i en DAG kalles tasks i Airflow. Det er to måter å lage tasks på, med operatorer eller med @task-annotasjon. Begge måtene blir vist i eksempelet under. Dersom du har et steg som skal kjøre Python-kode, bør @task-annotasjon benyttes. Ellers, for mer spesialiserte oppgaver, finnes det en del ferdige operatorer man kan benytte i sine tasks.
En enkel DAG kan for eksempel se slik ut:
from airflow.decorators import task
from airflow.operators.bash import BashOperator
from pipeline import SagaContext, make_pipeline
def pipeline(context: SagaContext):
# Tasks kan lages med operatorer
print_hello_task = BashOperator(task_id="print_hello", bash_command="echo hello")
# Eller med @task før en Python-funksjon
@task()
def print_world():
print("world")
print(context)
print_world_task = print_world()
# Avhengigheter mellom tasks settes med ">>".
# Slik det står her vil print_hello_task kjøre før print_world_task.
print_hello_task >> print_world_task
# Det er make_pipeline-funksjonen som faktisk oppretter DAG-en i Airflow.
make_pipeline(pipeline, schedule="@once")
DAG med Python-kode
Dersom du vil lage en DAG som kjører Python-kode, kan pipelinen se ut som under.
Merk også at eksempelet viser at data kan sendes mellom tasks. Dette fungerer for datatyper som tall, streng, bytes, dato, dictionary og pandas DataFrame. Vær oppmerksom på at dataene da vil mellomlagres i GCS, som introduserer noe forsinkelse. Unngå å sende enorme datamengder mellom tasks.
from pipeline import make_pipeline
from airflow.decorators import task
def pipeline(_):
# "@task"-annotasjon kan kun brukes når man vil kjøre Python-kode i en task. Dette kalles taskflow.
@task
def hello():
print("hello")
return "world"
@task
def print_something(input):
print(input)
# For taskflow vil rekkefølgen på kall bestemme avhengighetene.
# Slik det står her vil hello() kjøre før print_something(..).
output = hello()
print_something(output)
make_pipeline(pipeline)
DAG med SQL
Det er ganske vanlig å ville kjøre et sett med SQL-spørringer i en definert rekkefølge. Det kan se slik ut:
from airflow.providers.google.cloud.operators.bigquery import \
BigQueryInsertJobOperator
from pipeline import make_pipeline
def pipeline(_):
create_e6_stenginger = BigQueryInsertJobOperator(
task_id="create_e6_stenginger",
configuration={
"query": {
"query": """
CREATE OR REPLACE TABLE `{{ project_id }}.{{ dataset }}.stenginger_e6` AS
SELECT * FROM `saga-oppetid-prod-o6pj.curated.stenginger`
WHERE road = "E6"
""",
"useLegacySql": False,
}
},
)
stenginger_e6_i_2021 = BigQueryInsertJobOperator(
task_id="stenginger_e6_i_2021",
configuration={
"query": {
"query": """
CREATE OR REPLACE TABLE `{{ project_id }}.{{ dataset }}.stenginger_e6_i_2021` AS
SELECT * FROM `{{ project_id }}.{{ dataset }}.stenginger_e6` s
JOIN `saga-oppetid-prod-o6pj.curated.stenginginstanser` si ON si.stengingId = s.stengingId
WHERE DATE(si.startTime, 'Europe/Oslo') BETWEEN '2021-01-01' AND '2022-01-01'
""",
"useLegacySql": False,
}
},
)
create_e6_stenginger >> stenginger_e6_i_2021
# default_args blir sendt videre til både tasks og templates,
# eksempelvis i SQL
default_args = {
'dataset': 'examples'
# project_id er automatisk tilgjengelig på lik linje med andre
# default_args, basert på prosjektkonfigurasjonen i config.yml
}
make_pipeline(pipeline, default_args=default_args)
Det finnes flere eksempler i GitHub-repoet svvsaga/saga-pipelines.
Dersom du vil lære mer om hvordan DAGs fungerer, har vi skrevet om dette.
Regelmessig kjøring
Dersom du vil at din pipeline skal kjøre regelmessig kan man sende det med i det du lager pipelinen: make_pipeline(pipeline, schedule="@once"). Blant annet kan du velge mellom:
None: Kan bare trigges manuelt@once: Kjøres kun automatisk ved første deploy@hourly: Kjøres hver time@daily: Kjøres daglig- CRON-uttrykk
Les mer detaljert om skedulering av pipelines.
Hvordan lager man en DAG?
Lenger oppe på denne siden viser vi hvordan innmaten i en DAG kan se ut. Men hvilke steg må man gjøre for å opprette og kjøre en DAG? Det skildrer vi her.
Opprett DAG
Når du er klar til å lage en DAG starter du med å opprette en fil som slutter på .dag.py. Denne må ligge i mappen dags/<ditt team>/<domene>/. Domene her betyr typisk det faglige domenet man jobber innenfor, og enda mer konkret skal domene-delen helst være lik som "domenedelen" av ditt GCP-prosjekt. Som et eksempel har Yggdrasil et prosjekt som heter saga-oppetid[...], og derfor ligger tilhørende DAGs i dags/yggdrasil/oppetid/. Andre eksempler på domeneprosjekter: Trafikkdata, Oppetid, Trafikkapp, Reisetid, DDV, Vinterdrift. Du kan også se hvordan koden til alle Yggdrasil sine DAGs ser ut.
Opprett config-fil
For at din pipeline skal kjøre mot riktig domeneprosjekt må du opprette en config-fil med prosjekt-ID for STM og PROD. Denne skal ligge i samme mappe som domeneprosjektet, f.eks. oppetid, må hete config.yml, config.yaml eller config.json og kan se f.eks. slik ut:
STM:
default_project: saga-oppetid-stm-6cgp
PROD:
default_project: saga-oppetid-prod-o6pj
Hvis man bare har ett prosjekt, kan man sette dette prosjektet for både STM og PROD, slik du kan se under.
Dersom samme prosjekt brukes i STM og PROD må du vere bevisst på at det i utgangspunktet vil føre til at når pipelinen blir deployet til PROD vil en identisk pipeline kjøre i begge miljø. Altså vil disse to pipelines kjøre samtidig og lese og skrive de samme dataene i STM og PROD. Snakk med Yggdrasil for løsninger dersom du tror dette blir et problem.
STM:
default_project: saga-yggdrasil-analytics
PROD:
default_project: saga-yggdrasil-analytics
Dette kan man også gjøre for å kjøre en pipeline i ditt sandbox-prosjekt.
Valider DAG-en
Du kan gjøre en grunnleggende validering av DAG-en din som sjekker at imports er gyldige og at filnavnet er lovlig. Dette gjør du ved å kjøre:
./validate-dag.sh dags/<team>/<domene>/<dag>.dag.py
Kjør DAG-en lokalt
Når du har skrevet en DAG, kan du enten kjøre denne lokalt eller lage en pull request (PR) i saga-pipelines-repoet.
For å kjøre den lokalt har vi laget et script som bygger og kjører en DAG. Den brukes slik du ser under. Merk at om DAG-en din bruker tjenester i GCP må du ha satt opp autentisering med gcloud.
./run-dag.sh dags/<team>/<domene>/<dag>.dag.py
Dersom kommandoen over feilen med en feilmelding som nevner "no such table", prøv å kjøre kommandoen airflow db init først, og deretter prøv på nytt.
Lag pull request
Når man lager en PR til saga-pipelines vil DAG-en automatisk bli deployet til STM. Dette kan ta noen minutter. Når denne PR-en så blir flettet inn i main, blir DAG-en bli deployet til PROD.