Sagas datasoner
Av historiske årsaker finnes det to ulike prosjektstrukturer på Saga. Denne seksjonen omhandler den eldre strukturen hvor hvert team får utdelt sitt eget prosjekt med tilhørende datasoner. Denne strukturen finner du igjen i de ulike domeneprosjektene (STM, ATM, PROD og Analytics)
For ny struktur vil alle team på sikt jobbe på et felles prosjekt som i seg selv er datasoner, som fordrer til mer deling av data på tvers, se Dele data på Saga for mer informasjon
Soner, prosjekter og tilganger
I Google Cloud Platform (GCP) må alle ressurser, inkludert datalager, opprettes i et GCP-prosjekt. I tillegg er det slik at ulike typer data skal lagres i ulike datalagertjenester. Dermed vil ulike datasett tilsynelatende ligge spredt ut over ulike prosjekter og tjenester.
Generelt sett vil alle som har tilgang til et GCP-prosjekt kunne registrere sine datasett i ulike soner. Den som registrerer et datasett i en sone er "datasettets dataeier". Dataeier har ansvar for at datasettet tilfredsstiller føringer og krav som gjelder for en gitt sone.
Når trenger vi datasoner?
For tabeller og funksjoner som ikke skal deles i datakatalogen, står du fritt til å opprette egne datasett og kalle dem hva du vil. Det er altså bare tabeller som kan ha verdi for andre i Saga som bør ligge i de definerte datasonene.
Soneinndelingen Saga bruker
Vi har følgende datasoner på Saga:
rawstandardizedcurated
Tabeller som ligger i de definerte datasonene er i utgangspunktet delt med alle brukere på Saga.
Raw
Her ligger ulike typer rådata som ikke har blitt prosessert. Dette er typisk ustrukturerte data og strukturerte data som ikke har den strukturen vi ønsker på plattformen. Data lagres så lenge som mulig, eller så lenge det kan være behov for data, slik at deriverte data kan regenereres for eksempel i forbindelse med feil eller endringer som krever det.
- Eksempel: bilder, video, XML, CSV, JSON
- Foreslått lager: Google Cloud Storage eller BigQuery.
Standardized
I Standardized ligger data i en struktur med standardiserte datatyper. Data her har ikke vært gjennom særlig prosessering eller forretningslogikk utenom konvertering av datatyper og dataformat. Dataene i standardized gjør det enklere å utføre prosessering og sammenstille data, samt utføre analyse sammenlignet med det som ligger i raw.
Det er akseptabelt å ikke ta med alle felter fra datakilden dersom de åpenbart ikke er relevante eller dersom det medfører mye arbeid å få med alt.
- Eksempel:
- Fra gzippet XML til Avro-format
- Fra UTM33 til WGS84-koordinater
- Fra ulike datoformat til ISO8601 med tidssone
- Foreslått lager: BigQuery
Obs: Dersom du er usikker på om konvertering av data begynner å nærme seg forretningslogikk, er det sannsynlig at dataene heller bør plasseres i
curated.
Curated
Her har dataene gjerne blitt forandret av forretningslogikk, og kan være sammenstilt fra flere kilder. Sonen filtrerer gjerne vekk flere datapunkter enn i tidligere steg, og data har blitt kvalitetssjekket.
Datasett som ligger i denne sonen kan være klar og aktuell for at andre brukere av dataplattformen kan ta de i bruk. For mer informasjon om deling av data, se Dele data på Saga.
Data i denne sonen er godt beskrevet i tabellbeskrivelsen, og eventuelt også i datakatolgen. Beskrivelsen bør inkludere:
-
Datakvalitet
-
Datamodell
-
Hvor dataene kommer fra
-
Foreslått lager: Google Cloud Storage eller BigQuery.
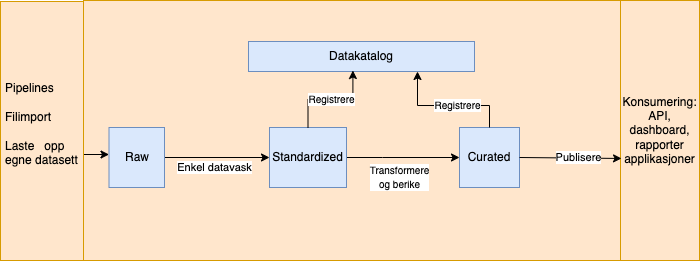
Typisk dataflyt
Figuren under illustrerer hvordan data forflyttes på Saga gjennom ulike soner med ulike prosesseringer. Enkel datavask kan være fjerning av duplikater, enkel standardisering av felter (f.eks strenger til tall) eller fjerning av overflødige kolonner. Figuren viser også at datasett fra sonene med forbedret datakvalitet kan bli registrert i datakatalogen.